
Prédiction d'usage de vélos Divvy
Machine Learning pour analyser et prédire l'usage des vélos en libre-service
Machine Learning pour analyser et prédire l'usage des vélos en libre-service
Ce projet de machine learning vise à prédire la demande horaire de vélos pour le système de vélos en libre-service Divvy de Chicago, qui compte plus de 700 stations et enregistre plus de 6 millions de trajets par an. L'objectif est d'anticiper les fluctuations de demande pour optimiser la redistribution des vélos, la planification de la maintenance et améliorer l'expérience utilisateur.
J'ai développé un pipeline complet de machine learning de bout en bout : de l'analyse de 11,3 millions de trajets historiques jusqu'au déploiement d'une application interactive avec Docker. Le modèle final atteint 90% de précision (R²) en combinant des données temporelles, météorologiques et calendaires.
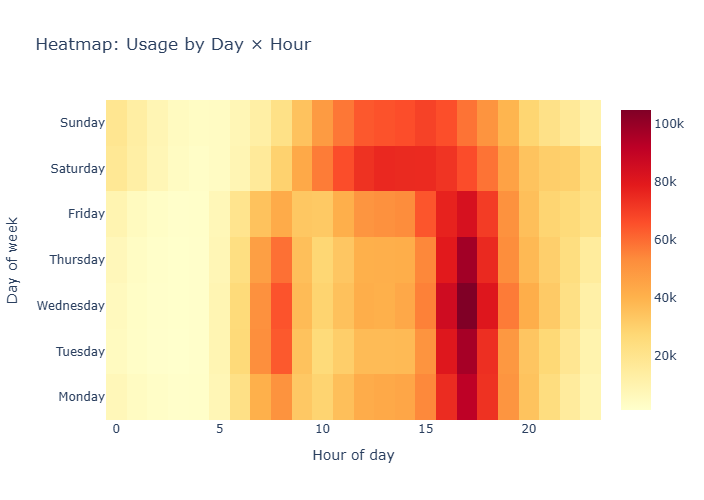
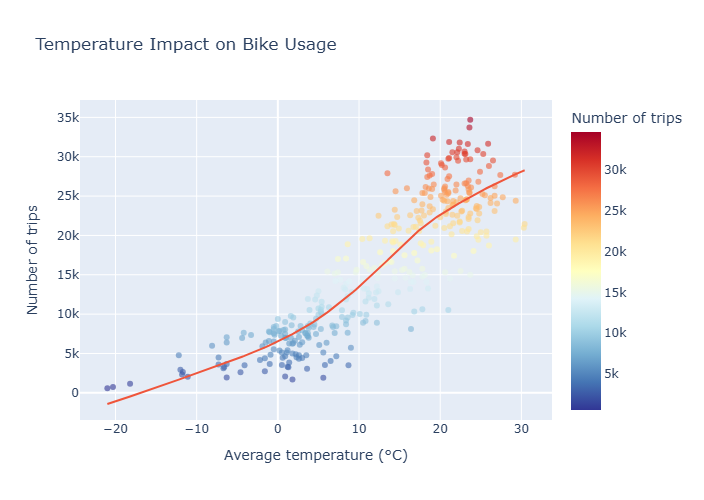
Le projet inclut une analyse exploratoire approfondie révélant les patterns d'usage (pics aux heures de pointe, impact de la météo), l'ingénierie de 15 features prédictives, la comparaison de 3 algorithmes de ML, et une validation rigoureuse sur des données de 2025 non vues. L'application Streamlit déployée permet de visualiser les prédictions et explorer les insights découverts.
Ce projet a été réalisé dans le cadre du cours de Machine Learning du M1 Data & AI à Ynov Paris (Janvier 2026) et a fait l'objet d'un rapport académique complet et d'une présentation orale.
Le projet suit une méthodologie rigoureuse de data science end-to-end en 4 phases :
Défi : Traiter 11,3 millions de lignes avec des contraintes mémoire
Solution : Utilisation d'opérations pandas optimisées (vectorisation), chargement par chunks, et agrégation précoce des données brutes en format horaire pour réduire de 11M à 8,8K lignes d'entraînement
Défi : Éviter le data leakage et valider sur des données futures réalistes
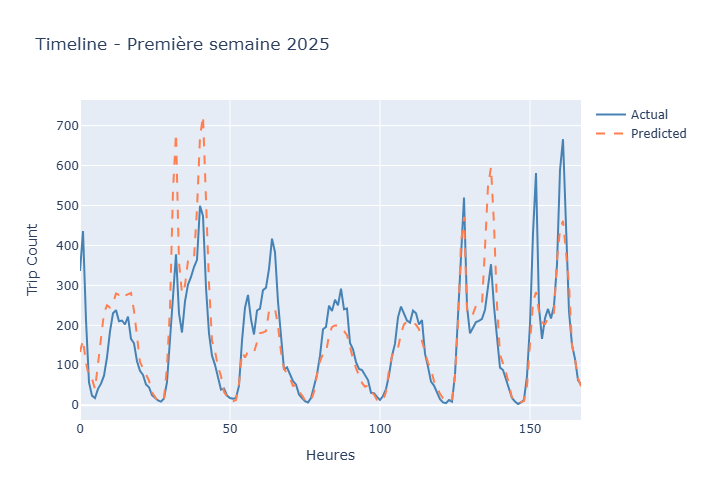
Solution : Split strict train/test respectant l'ordre temporel (2024 → 2025) sans mélange aléatoire, simulant une vraie mise en production avec prédictions sur données non vues
Défi : Fusionner des données de granularités différentes (trajets individuels + météo journalière + jours fériés)
Solution : Pipeline ETL structuré avec broadcast des données journalières vers résolution horaire, gestion des valeurs manquantes par interpolation, et création de clés de jointure temporelles cohérentes
Défi : Représenter la continuité temporelle (23h proche de 0h, décembre proche de janvier)
Solution : Encodage trigonométrique (sin/cos) pour les variables cycliques (heure, mois) permettant au modèle de capturer la continuité naturelle du temps
Défi : Garantir la reproductibilité et faciliter le déploiement pour les évaluateurs
Solution : Conteneurisation complète avec Docker (multi-stage build), Docker Compose pour orchestration, sauvegarde des modèles avec scalers (joblib), et documentation détaillée du setup
Défi : Choisir entre précision maximale et généralisation robuste
Solution : Analyse comparative rigoureuse montrant que Random Forest (R²_test=0.899) surpasse XGBoost (R²_test=0.896) en évitant le surapprentissage visible dans les écarts train/test, privilégiant la robustesse opérationnelle